

Growing into AI Builders
Announcing our partnership with Reforge


Every software company wants to become AI-native before they are disrupted by a frontier model. CEOs are trying to hire builders who can lead this new charge. If you are a PM looking for great career opportunities, your next interview will focus on your experience with AI agents. And if it does not, you are in the wrong room.
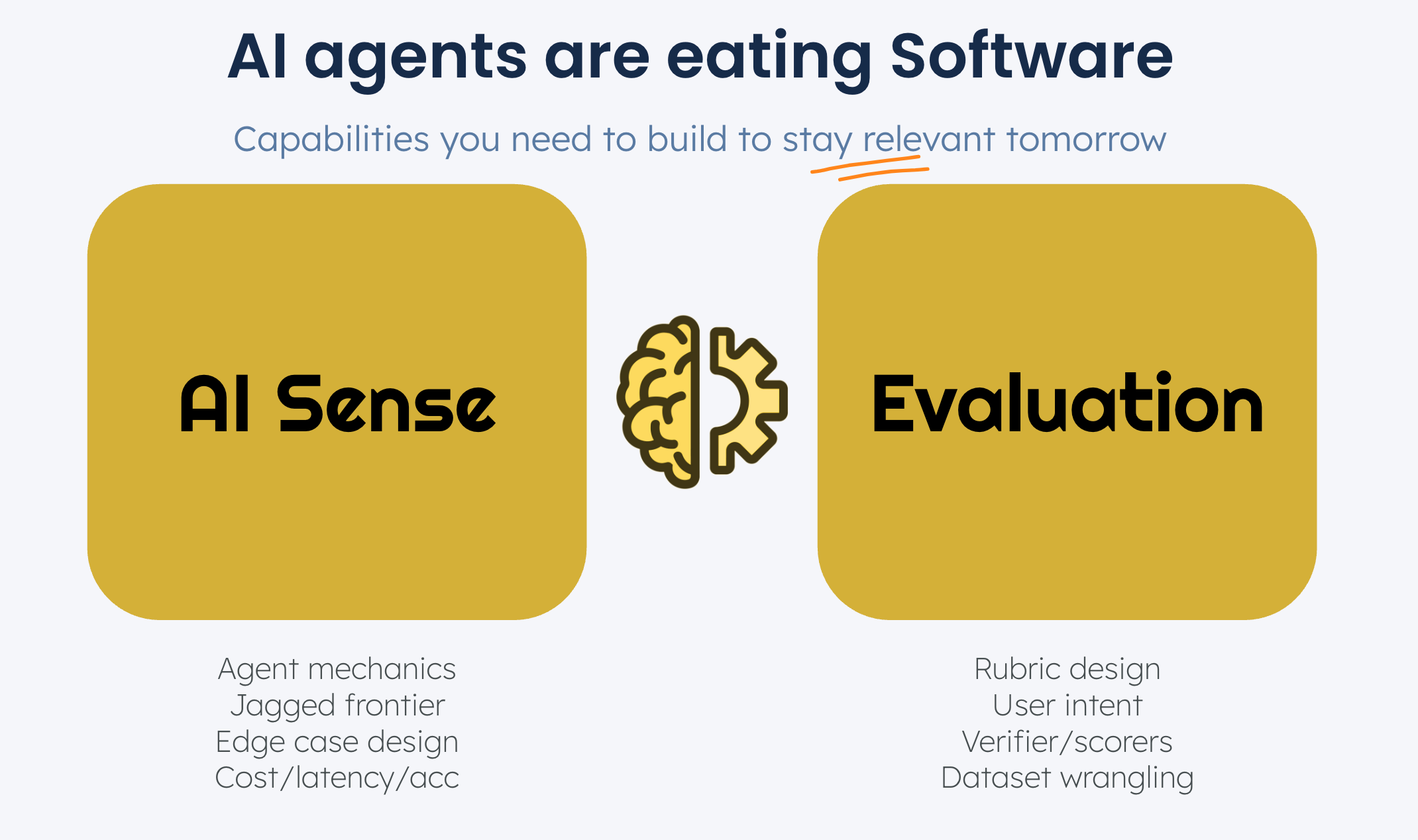
Agentic products are fundamentally different in nature. Whether you are leading, hiring or interviewing for an agentic product team, there are two new skills you need to learn - AI sense and Evaluation.
In this article, we dig deeper into what we mean by both.
Skill #1: AI Sense
As frontier models get better, it will require less and less skill for end consumers to use AI productivity tools in their day to day. There will be entire growth teams dedicated to optimizing the prompting experience and reducing friction for end users learning an AI tool for the first time. This has always been true in software.
The “alpha” for builders lies in knowing how things work under the hood. The value of understanding how agents work is already high and growing everyday. We have found that there are four distinct components to AI sense that are particularly important to PMs and Designers.
Agent mechanics: Understanding how agentic products manage their context, use tools, search for facts and update their memory (Eg: Langchanin on context engineering)
Jagged frontier: Having an intuition for what the real-world frontier model capabilities are (separate from the reported benchmarks) and where they break (eg: Ethan Mollick’s exploration)
UX design: Having a strong point of view on how agents should interact, fail gracefully/recover from errors or manage their level of access and autonomy with their human users
Performance: Understanding the trade offs between latency, accuracy and cost (eg: Epoch’s research)
Skill #2: Evaluation
Behind every successful agent product that has stood up to the test of time, is an AI Flywheel - a systematic way to ship and iteratively improve AI agents and LLM-powered products.

At the heart of that flywheel is a new skill - AI Evaluation. Users of AI products have wildly different experiences. Some love the product. Others get stuck or frustrated. The product team argues about whether quality is improving or not. No one can agree on where to focus or what to prioritize. Leadership wants to see steady progress, but what hill are we climbing?
This chaos is what happens when you try to manage a probabilistic system with deterministic tools. Your old playbook of PRD user stories, bug tickets, and A/B tests breaks down when every user gets a different output from the same input. Your old way of fixing bugs becomes a frustrating game of whack-a-mole with >50% of users never coming back.
AI Evaluation is the practical craft of defining, measuring, and improving the quality of AI-powered products. This skills has a few different components:
Rubric design: Defining quality metrics for agents that clearly align to user success (eg: Cursor’s Tab Accept Rate)
User intent mapping: UX research organized around user intent rather than workflows
Building Verifiers: Creative ways to help your team and your customers confirm the accuracy and safety of agent outputs (eg: Sierra’s simulation process)
Dataset management: Building datasets needed to iteratively improve products - golden outputs, edge cases and error modes
How it all comes together: a sample AI PRD
AI PRDs are a misnomer. They are no longer documents but living prototypes with the right quality metrics and datasets attached. Starting with prototypes requires AI Sense but helps capture real feedback and early failure modes for your agent.
AI agents need to be continuously calibrated and improved. They deliver work, not workflows which means that PMs need to spend more time in the solution space than they might previously have - as you will see in this PRD.
You can download the markdown file shown below here from Github: Sample-AI-PRD-Triage-Agent.md

Join us and learn by building
The only way to learn these skills is by building. Watching podcasts, youtube influencer videos farming your attention and scrolling twitter is not going to make anyone an AI Builder.
We are excited to announce that we are partnering with Reforge to launch a hands on Intro to AI Evals Course on their learning platform. Since we launched this course 2 weeks ago, it has already become their #1 program.
Join us for a free virtual lesson and demo this week. We will walk you step by step through the first step of building AI Sense and running Evals - Trace Analysis.
The "agents deliver work, not workflows" framing is interesting indeed, and the verifier examples (Sierra's simulation process, rubric design, dataset management) address the output quality dimension well.
There is a second evaluation dimension that surfaces when the agent's "work" includes actions on production systems: execution quality. When an agent updates a CRM record, triggers a deployment, or modifies a billing configuration, "was the output correct?" and "was the execution safe?" are two separate questions. Did the agent act within its authorized scope? Did it execute in the right order relative to other agents acting on the same system? Is there a record of what it did, when, and under what policy?
Building verifiers for output quality is hard but tractable: compare against golden datasets and human judgment. Building verifiers for execution quality is structurally different because the quality signal lives in the infrastructure layer, not in the agent's output. You need the execution record (what was done, in what order, by which agent, under what authority) to even define what "correct" means. Most teams I see are building the first type of verifier and discovering the second as a separate, harder problem once their agents start acting on shared production systems.