

Building an AI Product Flywheel
A system to systematically improve your enterprise agent after launch


TLDR;
Most enterprise AI agent launches end up stagnant - not improving much over time once shipped.
Regular roadmapping and product review processes don’t translate well to agents. AI product teams need to build a flywheel system to hill climb against a new kind of north star metric - agent success rate.
The most important new tool in this flywheel is trace analysis. Traces need to feed everything in AI development - from the debugging process, UX research, to an evaluation-driven roadmap.
This article outlines how.
Imagine this. Your team has just shipped a brand new AI agent to beta customers. It’s powered by Opus 4.5/GPT 5.2 and shows a ton of promise. You start getting mixed feedback - some users are in love with your agent while others are not able to get good results. Your marketing team wonders whether the agent is ready for primetime and sales is forwarding complaints from enterprise customers who will never try it again.
There are literally hundreds of things you could do next, how do you prioritize the right ones instead of playing whack-a-mole in product review meetings?
Shipping Enterprise-ready AI Agents
Launching AI products as a brand new startup in a small team is relatively easy - no one is paying attention. You can vibe check a focused value prop and rely on a small group of forgiving users to kick its tires.
But this approach doesn’t work when you are a large team with hundreds of enterprise customers. A newly launched agent gets immediate exposure to a firehose of diverse stakeholders and users with varying levels of AI savviness. They are each having unique experiences with your product and sharing unique kudos and concerns.
So how do you prioritize what’s next? Fixing the right bug, shipping the right new capabilities, etc. How do you even define new “features” when the underlying model is already more capable than what users are doing with it?
This is why most enterprise agent launches end up stagnant, while the outlier teams seem to get better every week. Much has been automated about writing code but building AI agents continues to be a laborious and fraught endeavor.
The AI Product Flywheel
The best AI products don’t magically start great, they build the flywheel system to consistently improve over time. Here’s what that roughly looks like in practice (no one-size-fits-all).
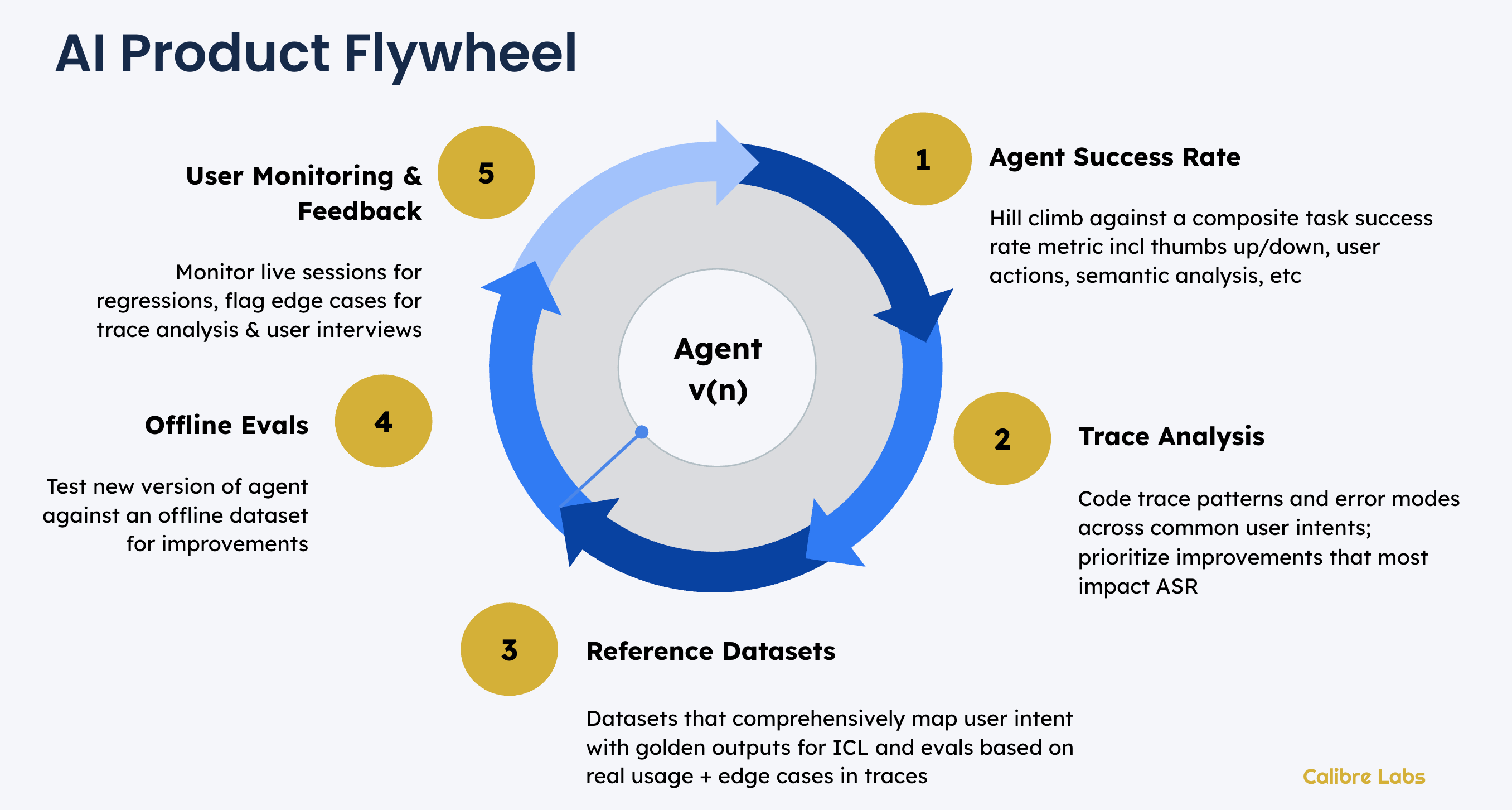
⭐️ Agent Success Rate - the new north star metric
Traditional software gave users workflows and our north star metrics measure how far along the happy path our users got. Agents deliver work, not workflows. This means we have completely new signals to use to come up with an “Agent Success Rate”.
This should be a composite metric that can take into account user feedback (thumbs), user actions, semantic analysis of the conversation and/or any task feedback. You will still be left with a significant portion of sessions with an unknown level of success - that’s ok, this uncertainty is our new reality.🔍 Trace Analysis - the new source of truth
Analyze a sample of traces aligned to each of the primary user intents you are designing your agent for. Langsmith’s CEO Harrison Chase recently wrote about how traces have become central documents in the AI development process and we couldn’t agree more.
Coding traces allows us to build a view of what error modes matter - and which to prioritize to most quickly improve our Agent Success Rate!🎙️Reference Datasets
Trace analysis reveals the gap between what you thought users are doing and the actual diversity of their interactions. A term borrowed from search analytics, user intent mapping allows you to categorize natural language inputs based on the user’s goals. For eg: the user intents for a customer support bot would include things like getting replacements, refunds, information vs updating sensitive information like payment.
Use these to create comprehensive reference datasets - including golden outputs and edge cases for evaluation.📐Offline Evals - unit tests for agents
Evals are unit tests for your agent and you must have them. It’s hard to make offline evals (especially for long running agents) realistic but the closer you can get, the faster you can ship.
Without reasonable offline evals, you simply can’t test small changes to your agent architecture and prompts. Realistic and well maintained offline evals are essential for getting better at context engineering as a team.⏺️ User Monitoring & Feedback - logging the signals
Real world AI usage is messy and often surprising for new features. Nothing can replace actual monitoring and (anonymized) semantic analysis of user sessions to make sure your agent is working in the wild. You can also now select user sessions that represent edge cases for follow ups. Combine these with direct feedback from support tickets and user interviews to track Agent Success Rate, closing the loop on our AI Flywheel.
Where do you start?
If you are like most of the teams we work with, you probably have bits and pieces of this system - some usage data, some dataset for evals, lots of qualitative user comments but not organized as trace codes. You probably don’t have a well structured user intent map.
If you have a significant user base, we recommend starting with #5 - user monitoring. Make sure you are collecting the data needed to start feeding the flywheel and work your way clockwise. If your user base is concentrated, start with #2 and kickstart evals based on user interviews.
2026 is the year that powerful agents change how each and everyone us is going to use software. Start building your flywheel and get ready for take-off.
Hey, great read as always. This 'flywheel' concept makes so much sense, especially about agent success rate. It reminds me of my Pilates practice – you need constant feeback to avoid stagnation, not just repeat motions. I wonder how tricy it is to truely get robust trace analysis going without drowning in data, but the idea is brilliant.