

AI evals are changing the PM craft
And SaaS product leaders need to plan ahead


The last time there was a seminal change in product management was 2008. Analytics defined a new generation of product leaders and those who didn’t embrace it were left behind. We can learn much from that era about exactly how AI evals will change the PM craft today.
The launch of Apple’s app store and 3rd party apps on Facebook gave birth to thousands of high growth startups and a new skill set for PMs - product analytics. The birth of the growth hacking movement was seeded by the very first examples of cohorted retention analysis and AARRR metric frameworks.
At first, the top PMs and growth hackers were those who learnt some SQL. By 2012, Facebook’s famous 7-friends-in-10-days heuristic was driving the adoption of new self-serve analytics tools for PMs like Amplitude. Today, no good product team would be caught without north star metrics. Every job-to-be-done shipped has adoption goals. Every UX funnel of behavioral events has its drop offs dissected.
AI is Work not Workflows
AI products haven’t changed the north star but they have certainly blown up the scope of using data to build better products. The product spec is now work, not workflows.
Instead of measuring ‘# users who completed the 5-step email creation flow,’ PMs need to ask, “Did the email meet our quality bar? How many edits were needed before the user sent the email we drafted?”.
Apps that used to have a few dozen happy paths now have countless personalized experiences. Describing the job-to-be-done feels inadequate when the product is a genie in a bottle. We need a way to apply some method to this madness - product evals.
In this post, the first in a series on the evolving face of AI-native product management, we cover 3 topics with examples and case studies from across the teams we advise:
What are AI product evals and why PMs should drive these
Why evals influence all AI product management workflows
How product leaders need to redesign their AI org to be eval-first
We ‘ll be covering each of these topics in more depth in our newsletter bi-weekly over the course of the next few months!
An overview of AI product evals
2024 saw a seminal shift in product craft with AI evals. AI CPOs like Kevin Weil, ML experts like Hamel and product content creators like Lenny have spoken/written extensively on the topic this year. There has been both rising confusion and curiosity on evals ever since, especially amongst PMs.
AI evaluation is the craft of scientifically observing and measuring the performance of an AI system against its stated goals. While the practice is not new and has deep roots in ML research, it is now an ubiquitously required skill as every product starts to incorporate LLM-driven features.
There are a few sources of confusion we observe in the ecosystem when it comes to AI evaluation:
The nuance to building good evals adapted to your domain and users is vastly under-appreciated. Out of the box evals, for metrics like “search relevance” or “helpfulness” need to be customized for your product taste as the team at Cresta illustrates with a simple example on accepting payments in support.
Many product leaders don’t know how their PMs should be driving/ contributing to evals - especially code-based ones, typically written in Python.
Evals are not an isolated skill. PMs need to change their entire workflow to be more iterative and eval-driven when building AI products.
Evals are used in nearly every stage of AI software development - from model training, context engineering, and monitoring to user research and product analytics.
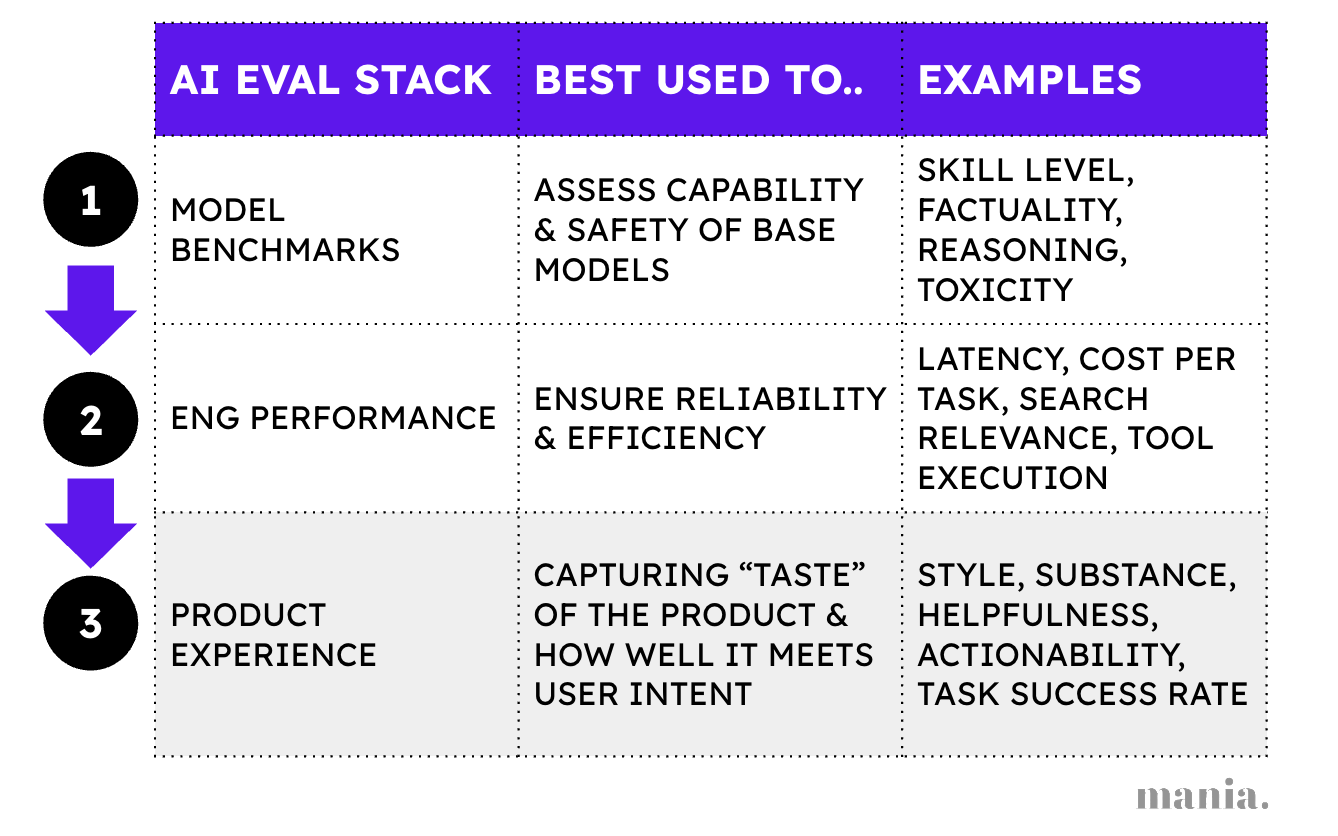
In practice, most enterprise developers get stuck in the first two layers, comparing models or untangling legacy systems and data pipelines. This can be a great opportunity for data leaders to step in and improve quality, as Irina Malkova, a product data executive, lays out in her article on Salesforce’s AI Help Agent.
For emerging AI-native products however, real differentiation happens in the third layer - where PMs decide what “great” means for user outcomes. This is where taste, judgment and empathy meet measurement.
When Amplitude launched their first AI feature (automated insights) - evals played a key role. Their Head of AI products, Yana Wellinder, shared that they chain together multiple prompts and tool calls for each AI workflow, evaluating how each step performs on its own, as well as how the full workflow does end-to-end.
Evals can take many different forms, each suited to different stages of the product life cycle - from systematic human vibe checks to autonomous user monitoring.
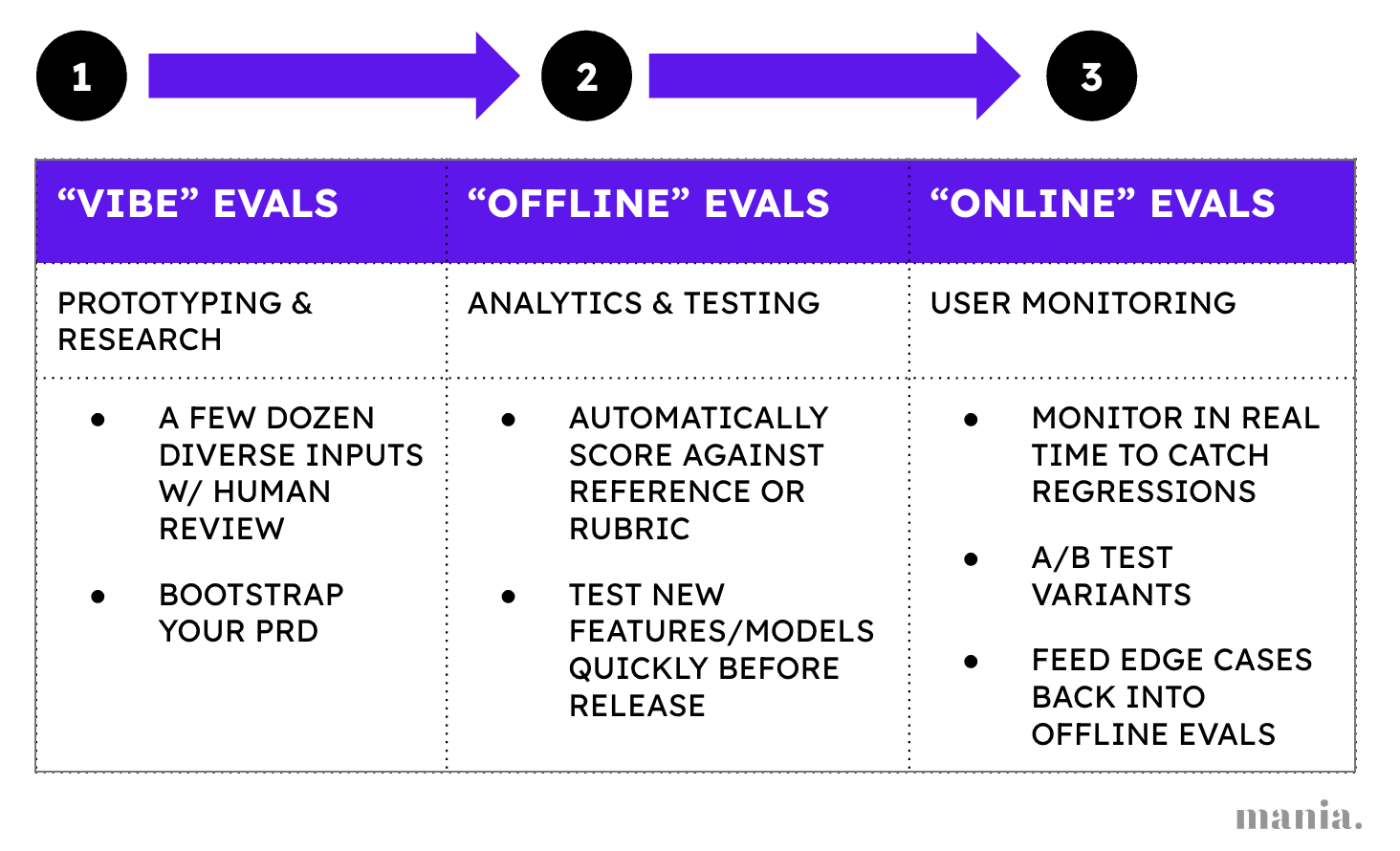
Vibe Evals: Also called vibe checks, every AI product requires an initial manual review of a prototype’s outputs with a small sample of input queries/use cases. This can also be data captured from design partners, during user research or with synthetic inputs. It gives you an immediate perspective on what quality goals you will need to set for your product and what use cases it’s strong and weak in.
Offline Evals: To test products before their release, we can measure performance against a reference dataset - either synthetic data or a set of historical user queries we have saved for “offline” evals. These automated evals can help us identify potential improvements and regressions in quality quickly.
Online Evals: The closest in spirit to monitoring, online evals are the LLM-era equivalent of A/B tests which are typically run on a sample of user queries at scale to track quality, detect regressions and compare model or prompt variants. They are critical because no offline eval is 100% realistic - your user needs and inputs are constantly changing. PMs should aim to collect edge cases from online evals and feed them back into offline reference datasets.
Limitations of automated evaluators
Automated evaluators - either code based on using an LLM-as-Judge - can only be used at scale if they have been aligned to human judgement. PMs should drive this to ensure evals reflect their product taste. For frontier features, it may not be possible to automate evals.
For instance, the team at Claude Code has found that automated benchmarks for their product have saturated and improvements now need to be evaluated manually.
Evals influence all AI Product Management workflows
While product evals leverage data, they aren’t just for measuring user experience. They impact every core product management workflow - user research, writing PRDs, testing and roadmap prioritization.
The primary driver of this change is how AI has rewired the role of software. The product is no longer a set of workflows but a system that delivers work. And since AI tools deliver work instead of workflows, PMs need to analyze and describe a different kind of job - the work output itself. They need to specify the requirements for the underlying system and a quality standard for the resulting work.
This is true for both stand alone AI agents as well as LLM-driven features embedded in existing products where the model is producing work.
LLMs add a new scientific dimension to every part of product development work - dataset curation.
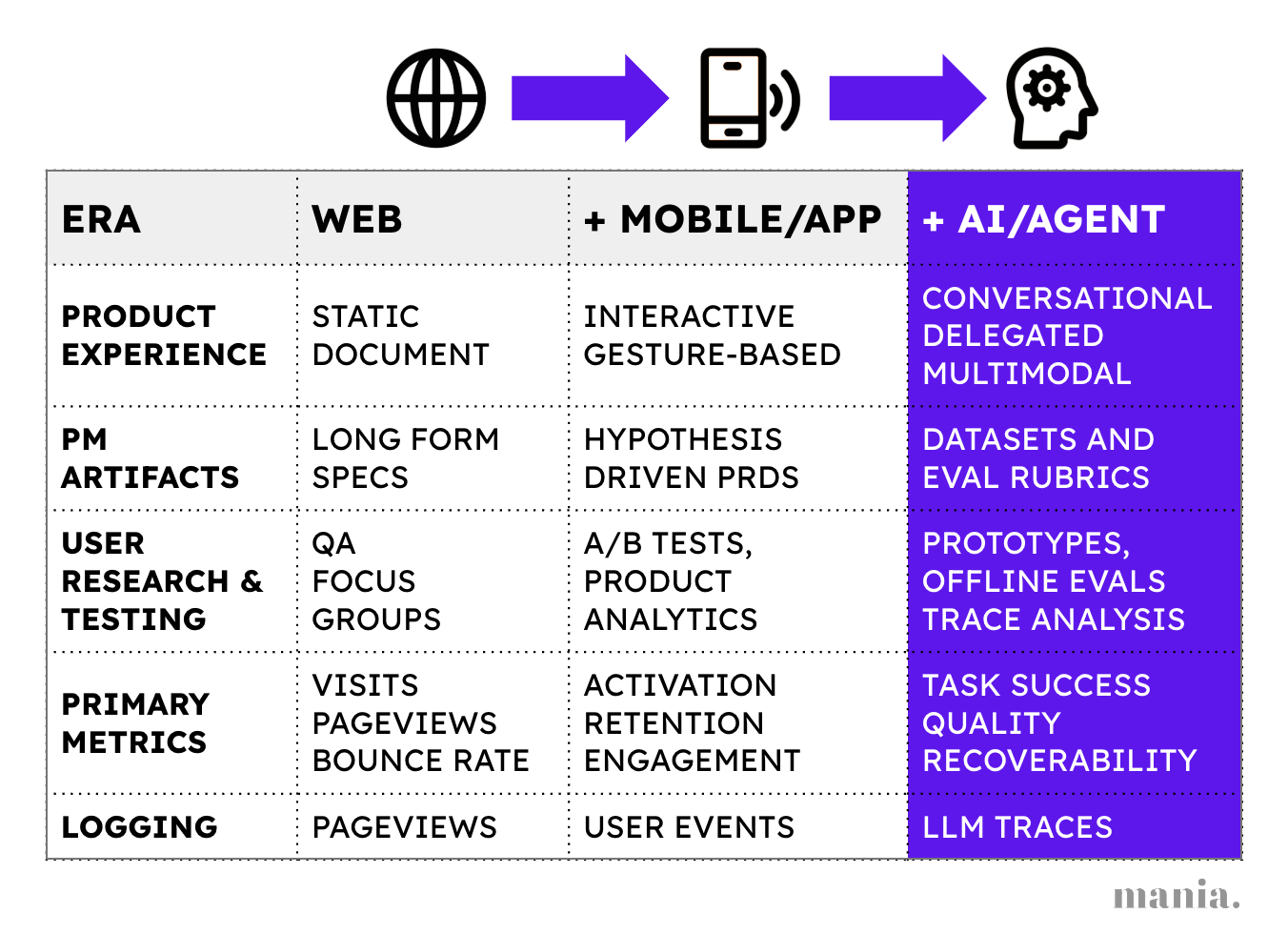
Below we step through each aspect of the PM role and how it’s impacted by inserting LLMs into a product architecture.
AI Customer development with reference outputs
Historically, customer development had two goals - validating the urgency of solving a particular problem and capturing the workflow required by them to do so. Today, the latter is replaced or augmented by examples of what the current best solution looks like. Like the team at Harvey, PMs must source these examples from subject matter experts and curate them to reflect their product strategy and taste. This should form the foundation of a reference dataset.
A great approach to building novel AI features is to sign up design partners to a vibe coded product. This was the approach Amr Shafik, Head of Product at AirOps, a leading AI martech company, took for their latest product launch on AEO brand visibility. It helped them bootstrap evals and understand usage. This accelerated their time to launch a production-grade feature and monetize it dramatically. .
AI PRDs with living datasets and eval rubrics
PRDs traditionally covered focus use cases and workflows. This seems quaint for AI features - especially those with open ended, conversational user inputs. No surprise that many AI-native teams like Gemini and Lovable have recently claimed they sometimes skip PRDs entirely to embrace a “build-first” culture.
PRDs will always play a critical role in clarifying the business problem that needs to be addressed. But there are a few aspects of PRDs that need to be completely rethought for AI products to make them relevant and helpful. The most important aspect is the job to be done. Instead of detailing user workflows, PRDs need:
Reference outputs. Every simple agent/AI feature needs 5-8 examples of great and poor outputs. Running vibe evals on prototypes before finalizing a PRD is the best way to choose these examples. These form the basis of an eval dataset engineering can use.
Product eval rubrics. PMs need to define the exact criteria for product experience evals (e.g., style, substance, helpfulness, task success rate) and align with ML Engineers on the methods (human-review, LLM-as-Judge, pairwise comparison) that they will explore to measure them.
Dataset Curation Plan: A strategy for continuously sourcing and curating new examples (from design partners, user feedback, or automated traces) to keep the eval dataset up-to-date and representative of user intent and product taste.
An AI PRD needs to become a living, dataset-infused spec with evals that describe the desired behavior and quality standard of the system, rather than a static list of functional specifications.
AI User Research with trace analysis
In the era of software delivering work, user research for PMs must be augmented with LLM trace analysis, which is the foundational first step of the iterative AI evaluation lifecycle.
A trace is the complete log/record of a user’s interaction with the AI system, capturing all inputs, model responses (both intermediate and final), tool calls, and associated metadata. Multi-turn traces are collected together with unique thread IDs.
Analyzing traces (ideally anonymized) to learn how users are interacting with your product is essential. Structured analysis results in two critical assets:
User Intent Maps for prompts. The AI version of journey mapping, user intent maps capture the goals of each persona and translate them into structured instructions for prompt layers in an LLM-driven product. They are best derived by analyzing traces to capture how users communicate the outcomes they need in diverse scenarios across agentic skills like search and tool use.
Trace Categories for evaluation. This process involves open coding initial observations and subsequently clustering them into categories for eval rubrics. The outcome is the definition of your product “taste,” a baseline for the Ai feature’s performance, and the raw, human-labeled data necessary to build a reliable “golden dataset” and the high-clarity rubrics for subsequent automated evaluators.
AI testing with offline product evals
Automated evaluation allows us to automate unit testing as well as integration testing for AI products. Once you have established trace categories and datasets that represent your product taste, new AI features can be tested - both for accuracy and quality - before each release or deployment. While vibe-checking a new version of the product can help us identify new trace categories to analyze, automated offline evals are the only way to fully understand how the product might behave at scale and affect thousands or millions of users everyday before you actually release it. When GPT-4o went sycophantic, it probably resulted in new offline evals getting added to pre-release testing.
Another benefit of offline evals is being able to compare your product output directly with that of competitors. While this is hard to do for use cases with proprietary customer data inputs, for many scenarios, you can run internal side by side comparisons to make sure you can deliver on your promise of a differentiated experience.
AI product analytics with effectiveness metrics
Traditional product analytics focused on user behavior. But when the product itself is the worker, engagement becomes a weak proxy for value. Instead, the signal that matters isn’t how often users interact but how effectively the product delivers on the work– how often the intended task is completed correctly, efficiently and safely.
Evals are how teams make those qualities measurable. PMs can now instrument quality itself and define what “correct”, “efficient” and “safe” mean by logging and analyzing everything the product does along the way, leading to new classes of product analytics:
CTR -> Task Success. Instead of only relying on how deep into a workflow the user journeyed, you can build evals that measure the quality of the output directly. This makes it clearer who is and isn’t getting value from the product, and can highlight edge cases where tasks fail that feed future rounds of user research.
NPS survey -> In-product sentiment. Conversational AI products can detect satisfaction or frustration from user tone and phrasing, turning semantic signals into real-time quality feedback. When aggregated across users, these signals surface patterns of frustration that point to usability gaps or missing capabilities. It continues to be critical to constantly capture as much real user feedback on output as possible (thumbs up/down) and leverage to identify the right cohorts to analyze deeply.
App Retention -> Agent Retention. In traditional apps, retention meant users returning to spend time in the product. With agents, it now means returning to delegate work—often through Slack, MCP, or another integrated tool rather than the app itself. This shift changes what predicts retention: evals that track output quality, such as how consistently the agent completes tasks correctly, efficiently and safely, become the clearest leading indicators even when users never open the app.
Arnav Sharma, the CTO of Enterpret, shares that they get notified on Slack for each user downvote, so they can add failure cases immediately to their trace analysis backlog.
To accomplish this requires comprehensive logging of traces that capture each reasoning step, tool call and user correction. These traces become the new atomic unit of product data and transform analytics from counting clicks and events to understanding decisions and outcomes.
Redesigning your AI Product Org to be Eval-first
Unfortunately most product teams are not set up to operate this way. Incumbent software companies that found product market fit before 2022 are desperately looking for AI-native product leaders who can help transform their product development process from the ground up.
We need to focus our efforts on what’s fundamentally new: golden outputs replace workflow documentation, datasets and evals become core product artifacts, trace analysis augments traditional user research, and task success rate supersedes funnel metrics. Create a self-improving system where data curation is as critical as shipping features.

Just as analytics defined the winning product teams of the 2010s, product evals will separate tomorrow’s leaders from those who fall behind. To redesign your cross functional development process for shipping AI products, leverage these three principles:
Start with Data. Whether it’s prototyping, building or optimizing a product after launch, prioritize collecting and organizing datasets that represent your product’s output. This should be the primary purpose of building prototypes. Prioritize internal admin tools that make it trivially easy to analyze and label traces.
Iterate on the System. Teams building AI apps can only learn by cycling rapidly through versions of the whole product and evaluation system together. AI development is not just about prompt engineering but optimizing a system that delivers work. Ensure that your entire team understands the complete system.
Lead from the trenches. Our general observation working with many AI SaaS companies is that product team leaders need to invest in learning these skills themselves. Whether it’s prototyping or evals, learning from personal experience and encouraging your team to do the same is paramount.
Just like vanity metrics, it’s trivially easy to have vanity evals that check the box and don’t do anything to improve your AI system’s quality. Sit with engineers to analyze traces together - you will see how different perspectives and customer empathy can radically change how your AI product gets built. Write your own eval rubrics - don’t just delegate it to ML engineers. Feel the friction of having to categorize ambiguous edge cases.
This redesign won’t be comfortable but the teams that make product evals central to their PM craft will build AI products that genuinely deliver value, while others ship demos that don’t stand up to scrutiny.
Comment/subscribe or DM us if you are leading an AI product org and this is top of mind for you. We would love to collaborate!
Thank you to Brent Tworetzky (Peloton), Irina Malkova (Salesforce), Sudhee Chailappagari (Battery Ventures), Yana Wellinder (Amplitude), Amr Shafik (AirOps), Arnav Sharma (Enterpret) and Barron Ernst (Troon) who reviewed earlier drafts of this post to share anecdotes and feedback with us.
Excited to keep building out our Eval suite - thank you for the awesome post! Gives us a lot of clear language and examples to communicate with the broader team as this shift is underway. Great work!
The shift from specifying workflows to specifying work outputs resonates strongly. Thank you for sharing what you've learnt and observed!